[conflicted] Will prefer dplyr::filter over any other package.
[conflicted] Will prefer dplyr::select over any other package.
[conflicted] Will prefer dplyr::slice over any other package.
[conflicted] Will prefer dplyr::rename over any other package.
[conflicted] Will prefer dials::neighbors over any other package.
[conflicted] Will prefer parsnip::fit over any other package.
[conflicted] Will prefer parsnip::bart over any other package.
[conflicted] Will prefer parsnip::pls over any other package.
[conflicted] Will prefer purrr::map over any other package.
[conflicted] Will prefer recipes::step over any other package.
[conflicted] Will prefer themis::step_downsample over any other package.
[conflicted] Will prefer themis::step_upsample over any other package.
[conflicted] Will prefer tune::tune over any other package.
[conflicted] Will prefer yardstick::precision over any other package.
[conflicted] Will prefer yardstick::recall over any other package.
[conflicted] Will prefer yardstick::spec over any other package.
── Conflicts ──────────────────────────────────────────── tidymodels_prefer() ──
Loading required package: grid
Loading required package: mvtnorm
Loading required package: modeltools
Loading required package: stats4
Attaching package: 'modeltools'
The following object is masked from 'package:tune':
parameters
The following object is masked from 'package:parsnip':
fit
The following object is masked from 'package:infer':
fit
The following object is masked from 'package:dials':
parameters
Loading required package: strucchange
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
Loading required package: sandwich
Attaching package: 'strucchange'
The following object is masked from 'package:stringr':
boundary
Rows: 96 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): source
dbl (2): percent_hens, percent_eggs
date (1): observed_month
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
egg<-read_csv(here("data", "egg-production.csv"))
Rows: 220 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): prod_type, prod_process, source
dbl (2): n_hens, n_eggs
date (1): observed_month
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Look at Data sets
head(cage)
# A tibble: 6 × 4
observed_month percent_hens percent_eggs source
<date> <dbl> <dbl> <chr>
1 2007-12-31 3.2 NA Egg-Markets-Overview-2019-10-19.pdf
2 2008-12-31 3.5 NA Egg-Markets-Overview-2019-10-19.pdf
3 2009-12-31 3.6 NA Egg-Markets-Overview-2019-10-19.pdf
4 2010-12-31 4.4 NA Egg-Markets-Overview-2019-10-19.pdf
5 2011-12-31 5.4 NA Egg-Markets-Overview-2019-10-19.pdf
6 2012-12-31 6 NA Egg-Markets-Overview-2019-10-19.pdf
head(egg)
# A tibble: 6 × 6
observed_month prod_type prod_process n_hens n_eggs source
<date> <chr> <chr> <dbl> <dbl> <chr>
1 2016-07-31 hatching eggs all 57975000 1147000000 ChicEggs-09-23-…
2 2016-08-31 hatching eggs all 57595000 1142700000 ChicEggs-10-21-…
3 2016-09-30 hatching eggs all 57161000 1093300000 ChicEggs-11-22-…
4 2016-10-31 hatching eggs all 56857000 1126700000 ChicEggs-12-23-…
5 2016-11-30 hatching eggs all 57116000 1096600000 ChicEggs-01-24-…
6 2016-12-31 hatching eggs all 57750000 1132900000 ChicEggs-02-28-…
Note: Within the egg data set, the value ‘all’ includes cage-free and conventional housing.
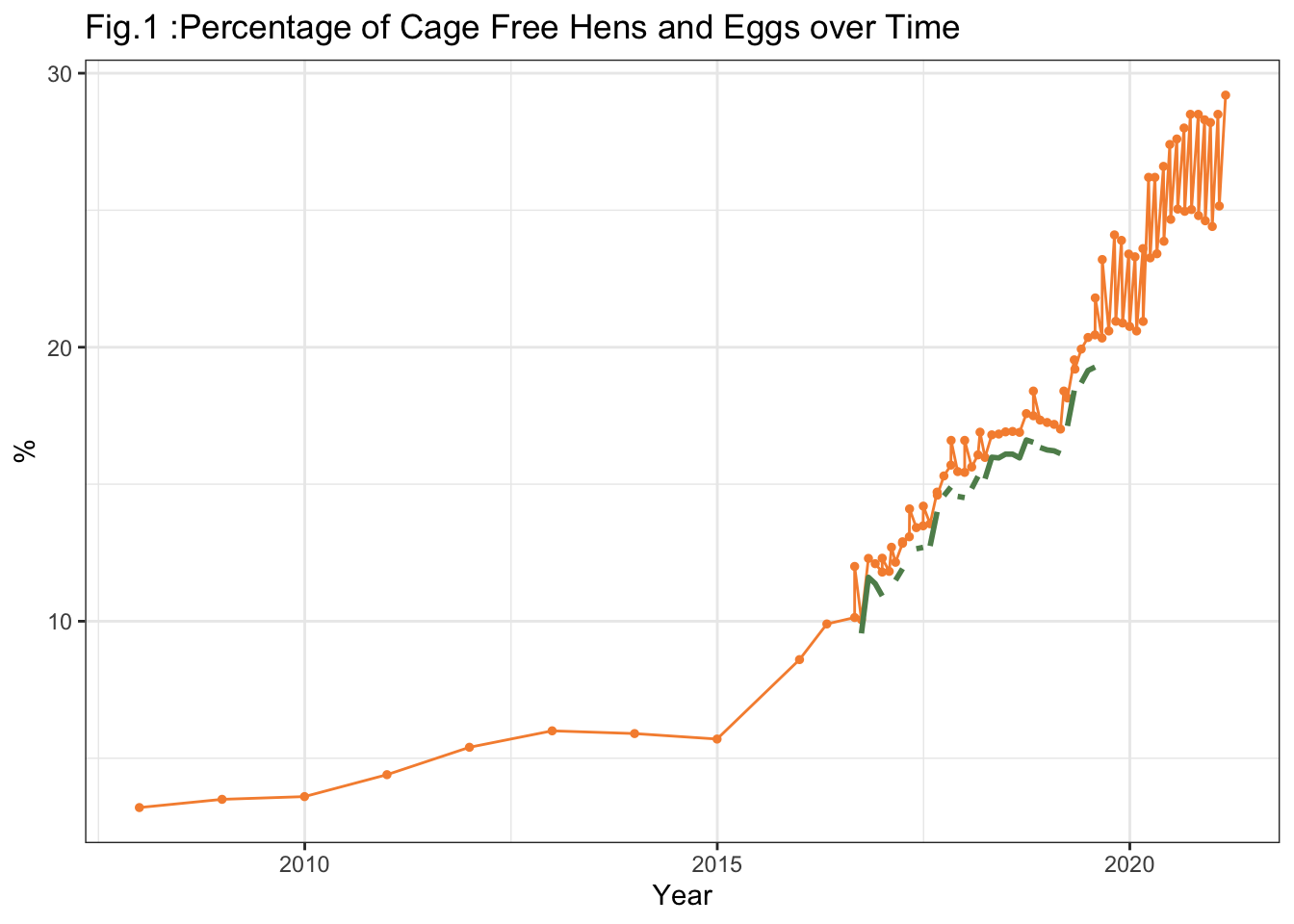
Percentage of Hens are in orange, and percentage of eggs are in green. We see an increase in percentage of cage free eggs and hens over time.
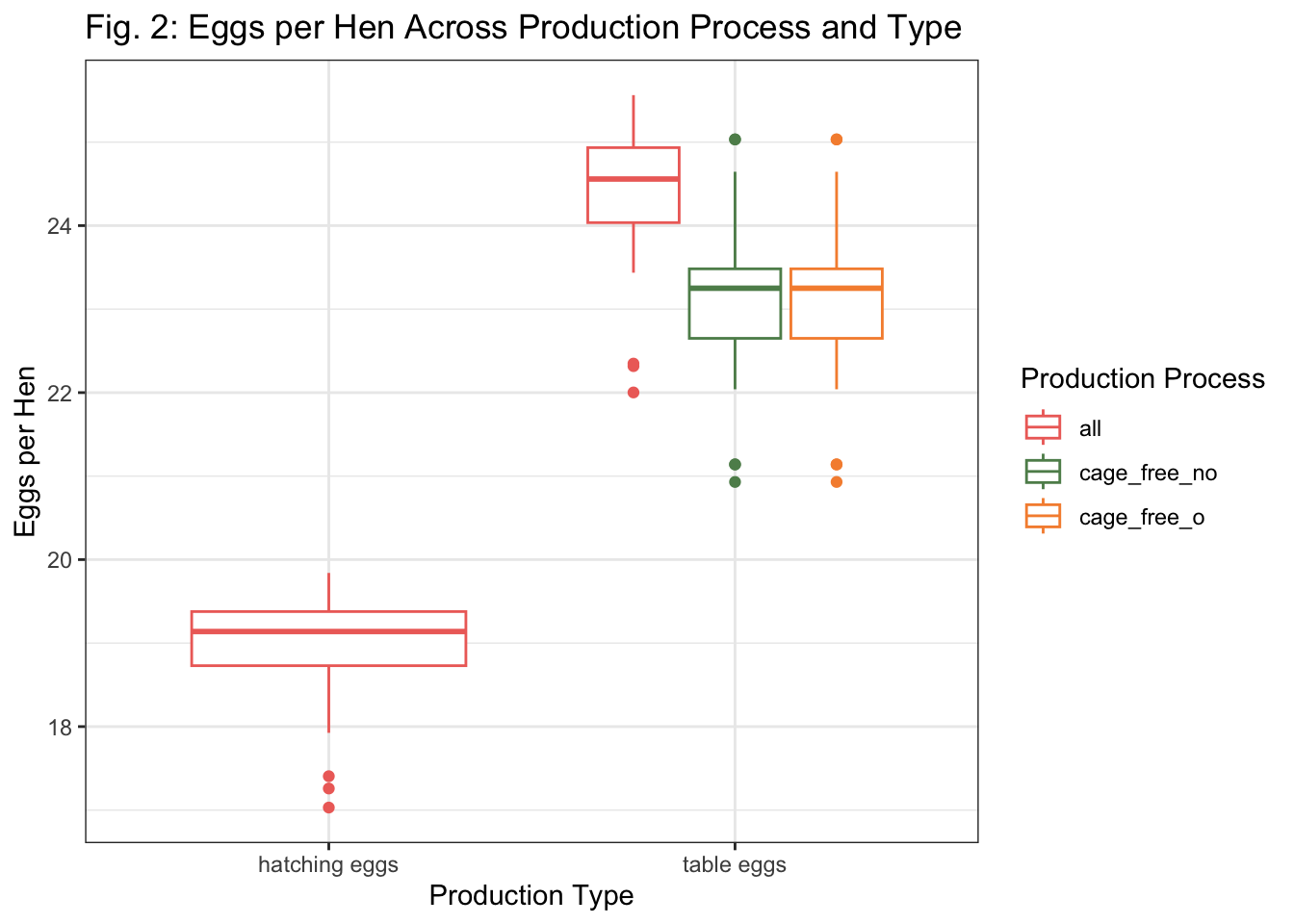
Fig. 2: Eggs per Hen across production type and process
egg %>%ggplot() +geom_boxplot(aes(x = prod_type,y = egg_hen,color = prod_process)) +theme_bw()+labs(title ="Fig. 2: Eggs per Hen Across Production Process and Type",x ="Production Type",y ="Eggs per Hen",color ="Production Process") +scale_color_manual(values =c(all ="#ee6f68",cage_free_no ="#5e8d5a",cage_free_o ="#f68f3c"))
Figure 2 depicts a stark difference in the number eggs per hen between hatching eggs and table eggs. No difference is observed between the production processes within the table eggs.
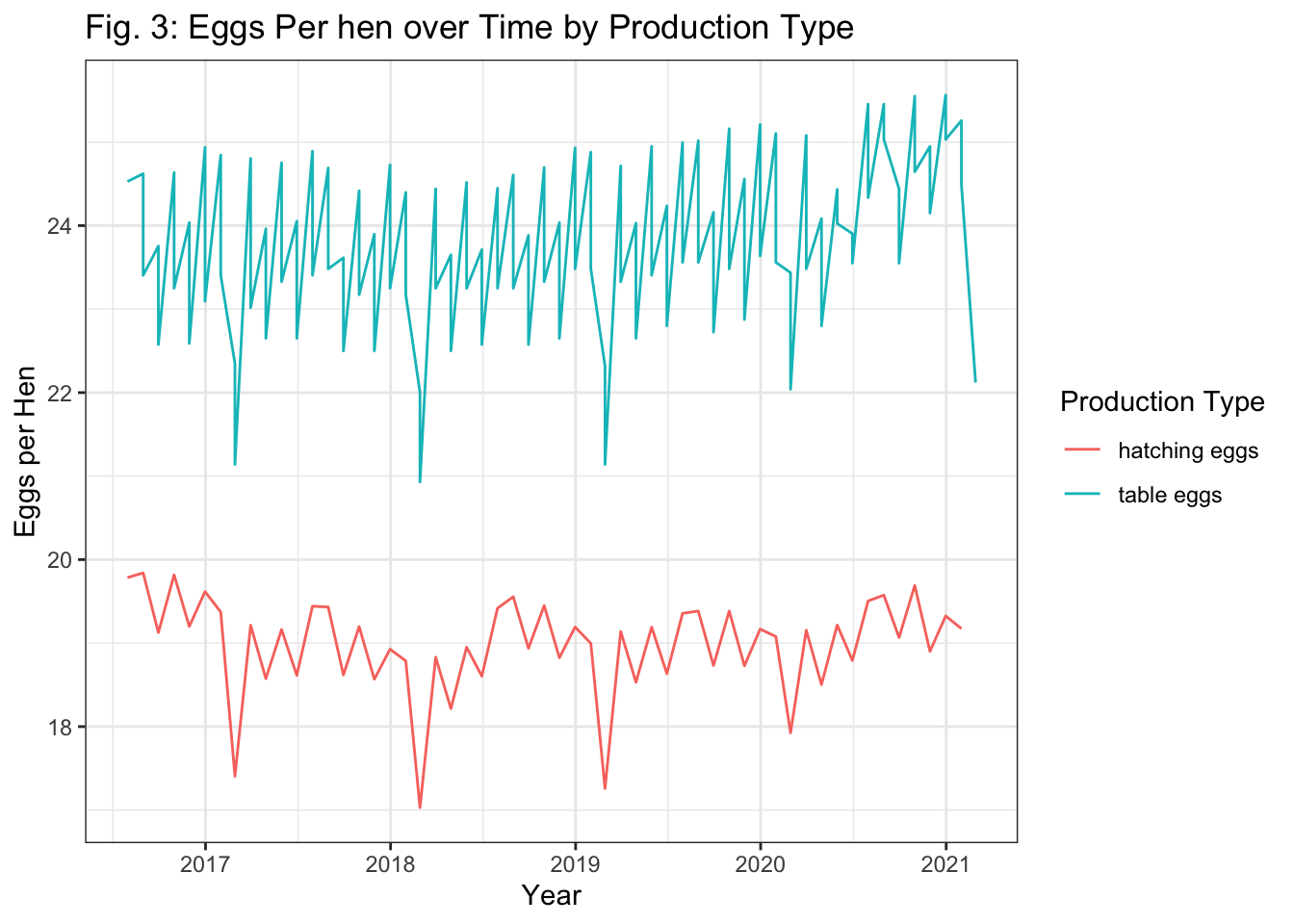
Fig. 3: Eggs per hen over time
egg %>%ggplot() +geom_line(aes(x = observed_month,y = egg_hen,color = prod_type)) +theme_bw()+labs(x ="Year",y ="Eggs per Hen",title ="Fig. 3: Eggs Per hen over Time by Production Type",color ="Production Type")
Similarly, Figure 3 shows that more eggs per hen are produced from the table eggs process.
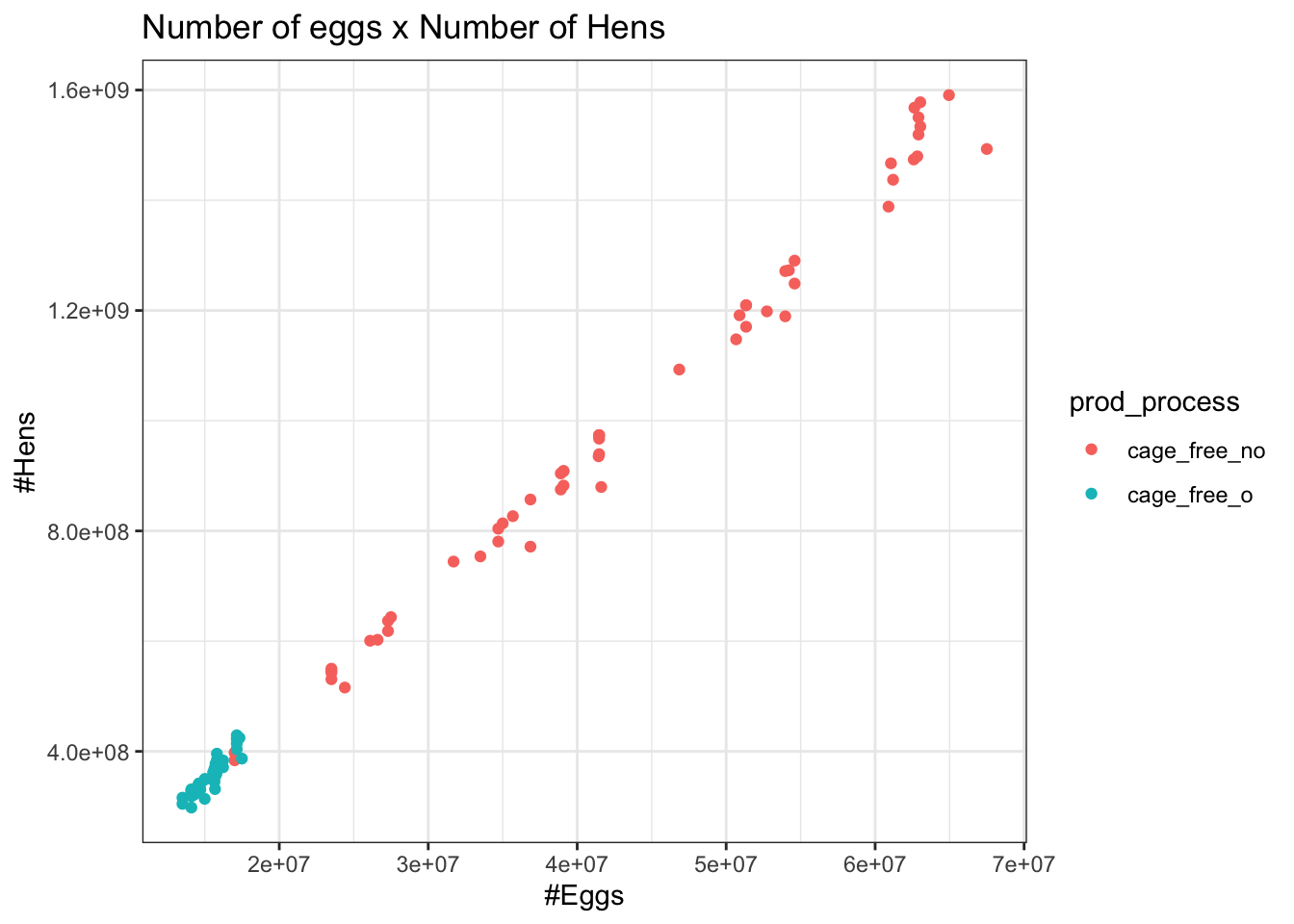
Fig.4 Eggs x Hens
p<- egg %>%filter(prod_type %in%"table eggs",!prod_process %in%"all") p %>%ggplot() +geom_point(aes(x = n_hens,y = n_eggs,color = prod_process)) +theme_bw()+labs(x ="#Eggs",y ="#Hens",title ="Number of eggs x Number of Hens")
This is a very linear correlation- but not a very interesting question.
Question/Hypothesis:
Because a higher portion of the population consumes eggs as opposed to hatching chicks, and due to the energetically taxing/limiting process of hatching, we expect to see a significantly higher effort towards the production of table eggs as opposed to hatching eggs.
Predictor: Production Type (Hatching or Table Eggs)
Outcome: Eggs per hen
Final Cleaning
We will use only the egg dataset.
Remove Columns that are not needed for analysis
egg <- egg %>%select(prod_type, egg_hen)
Split into Test and Train Set
# Fix the random numbers by setting the seed # This enables the analysis to be reproducible when random numbers are used set.seed(222)# Put 3/4 of the data into the training set data_split <-initial_split(egg, prop =3/4)# Create data frames for the two sets:train <-training(data_split)test <-testing(data_split)
Modeling
0. NULL MODEL
5-Fold Cross Validation
fold_egg_train <-vfold_cv(train, v =5, repeats =5, strata = egg_hen)fold_egg_test <-vfold_cv(test, v =5, repeats =5, strata = egg_hen)
Warning: The number of observations in each quantile is below the recommended threshold of 20.
• Stratification will use 2 breaks instead.
The number of observations in each quantile is below the recommended threshold of 20.
• Stratification will use 2 breaks instead.
The number of observations in each quantile is below the recommended threshold of 20.
• Stratification will use 2 breaks instead.
The number of observations in each quantile is below the recommended threshold of 20.
• Stratification will use 2 breaks instead.
The number of observations in each quantile is below the recommended threshold of 20.
• Stratification will use 2 breaks instead.
! Fold1, Repeat1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2, Repeat1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3, Repeat1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4, Repeat1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5, Repeat1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold1, Repeat2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2, Repeat2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3, Repeat2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4, Repeat2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5, Repeat2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold1, Repeat3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2, Repeat3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3, Repeat3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4, Repeat3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5, Repeat3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold1, Repeat4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2, Repeat4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3, Repeat4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4, Repeat4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5, Repeat4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold1, Repeat5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2, Repeat5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3, Repeat5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4, Repeat5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5, Repeat5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 2.18 25 0.0106 Preprocessor1_Model1
2 rsq standard NaN 0 NA Preprocessor1_Model1
! Fold1, Repeat1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2, Repeat1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3, Repeat1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4, Repeat1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5, Repeat1: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold1, Repeat2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2, Repeat2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3, Repeat2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4, Repeat2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5, Repeat2: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold1, Repeat3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2, Repeat3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3, Repeat3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4, Repeat3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5, Repeat3: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold1, Repeat4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2, Repeat4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3, Repeat4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4, Repeat4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5, Repeat4: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold1, Repeat5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold2, Repeat5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold3, Repeat5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold4, Repeat5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
! Fold5, Repeat5: internal:
There was 1 warning in `dplyr::summarise()`.
ℹ In argument: `.estimate = metric_fn(truth = egg_hen, estimate = .pre...
= na_rm)`.
Caused by warning:
! A correlation computation is required, but `estimate` is constant an...
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 2.19 25 0.0838 Preprocessor1_Model1
2 rsq standard NaN 0 NA Preprocessor1_Model1
RMSE = 2.19 and STD_ERR = 0.084
1. LINEAR MODEL
Run Model
#Set up linear modellm_mod<-linear_reg() %>%set_engine("lm") %>%set_mode("regression")#Workflow that adds recipe to modellm_wflow<-workflow() %>%add_model(lm_mod) %>%add_recipe(egg_rec_train)#Use workflow to fit model to data setegg_fit<- lm_wflow %>%fit(data = train)#View as Tibble egg_fit %>%extract_fit_parsnip() %>%tidy()
Joining with `by = join_by(.metric, .estimator, .estimate)`
metrics
# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.873
2 rsq standard 0.840
RMSE = 0.87
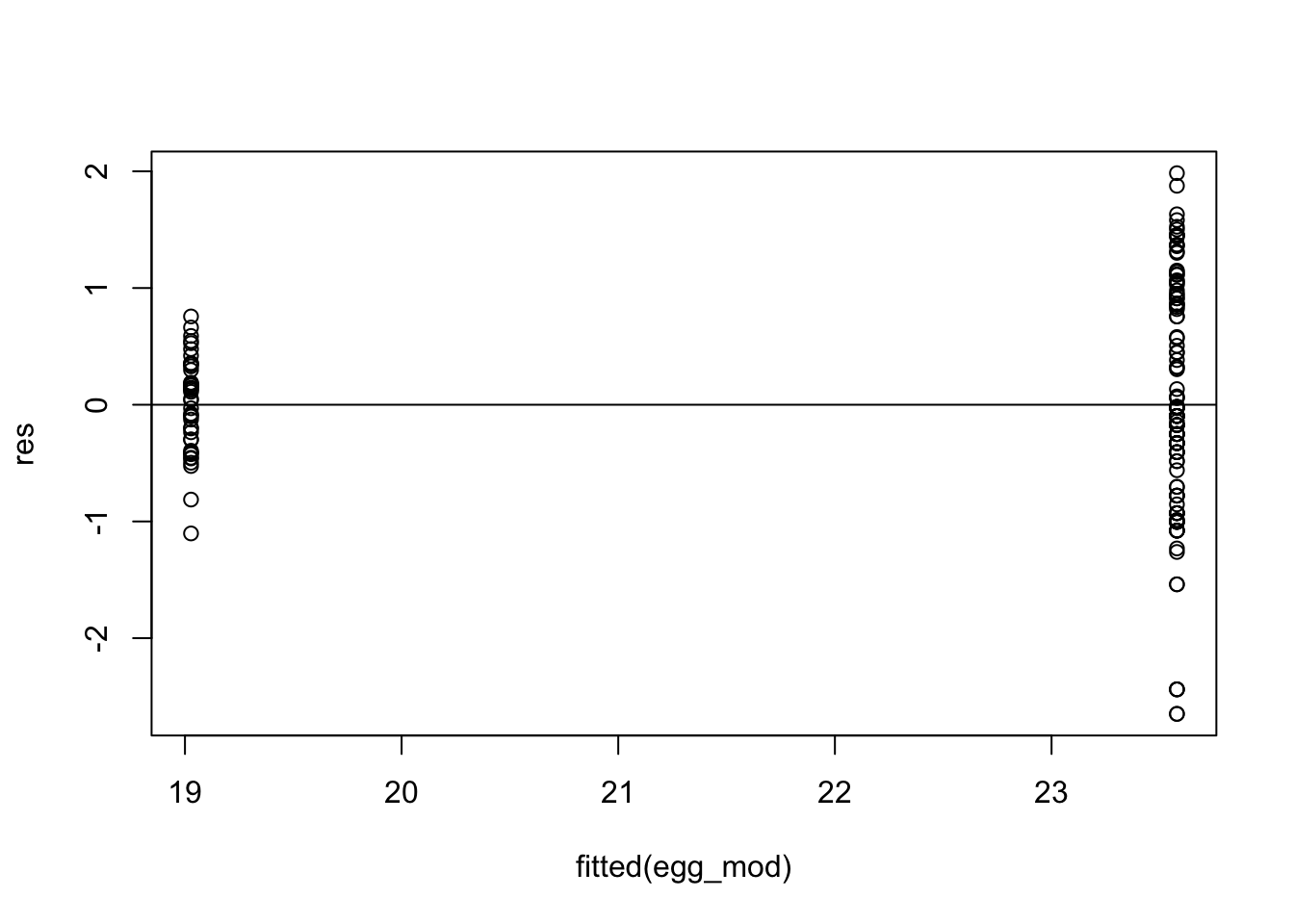
Residuals
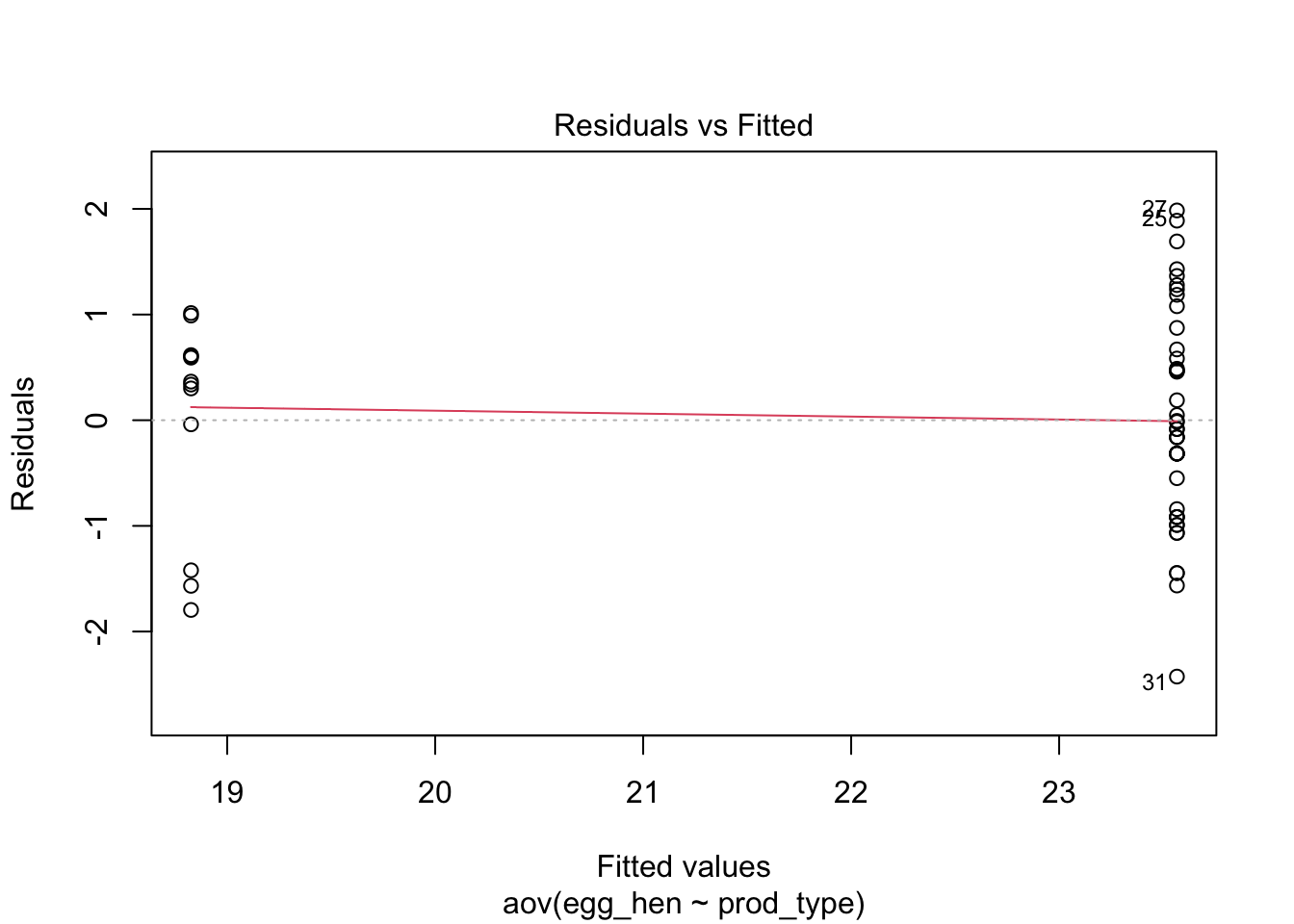
egg_mod<-lm(egg_hen ~ prod_type, data = train)res<-resid(egg_mod)plot(fitted(egg_mod), res)abline(0,0)
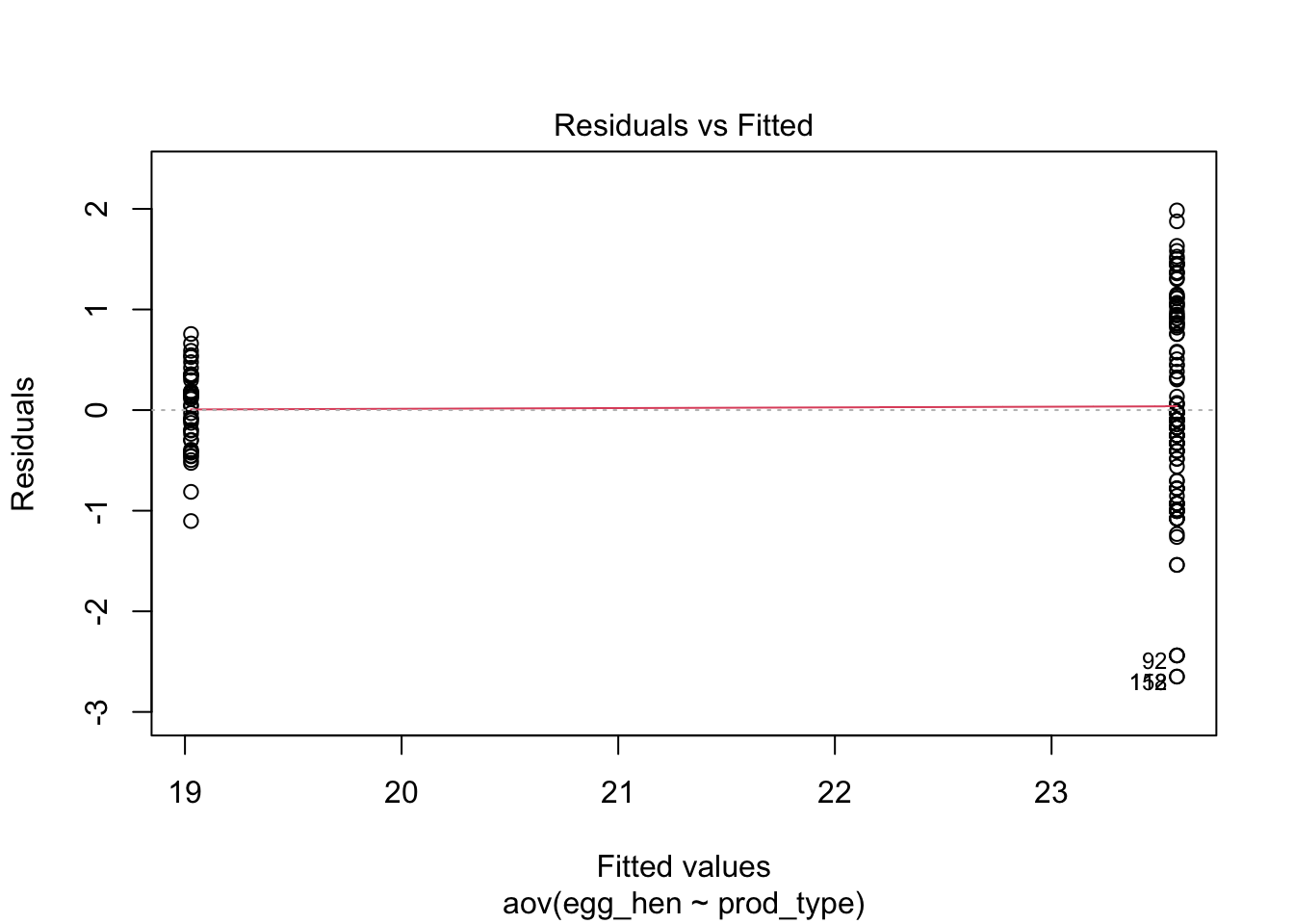
2. ANOVA MODEL
ANOVA is a statistical test for estimating how a quantitative dependent variable changes according to the levels of one or more categorical independent variables. ANOVA tests whether there is a difference in means of the groups at each level of the independent variable.
Null
#Modelanova_n<-aov(egg_hen ~1, data = egg)summary(anova_n)
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 219 1050 4.796
Decision Tree Model Specification (regression)
Main Arguments:
cost_complexity = tune()
tree_depth = tune()
Computational engine: rpart
Think of tune() here as a placeholder. After the tuning process, we will select a single numeric value for each of these hyperparameters. For now, we specify our parsnip model object and identify the hyperparameters we will tune().
We can create a regular grid of values to try using some convenience functions for each hyperparameter:
#create a regular grid of values for using convenience functions for each hyperparameter.tree_grid_dtree <-grid_regular(cost_complexity(), tree_depth(), levels =5)tree_grid_dtree
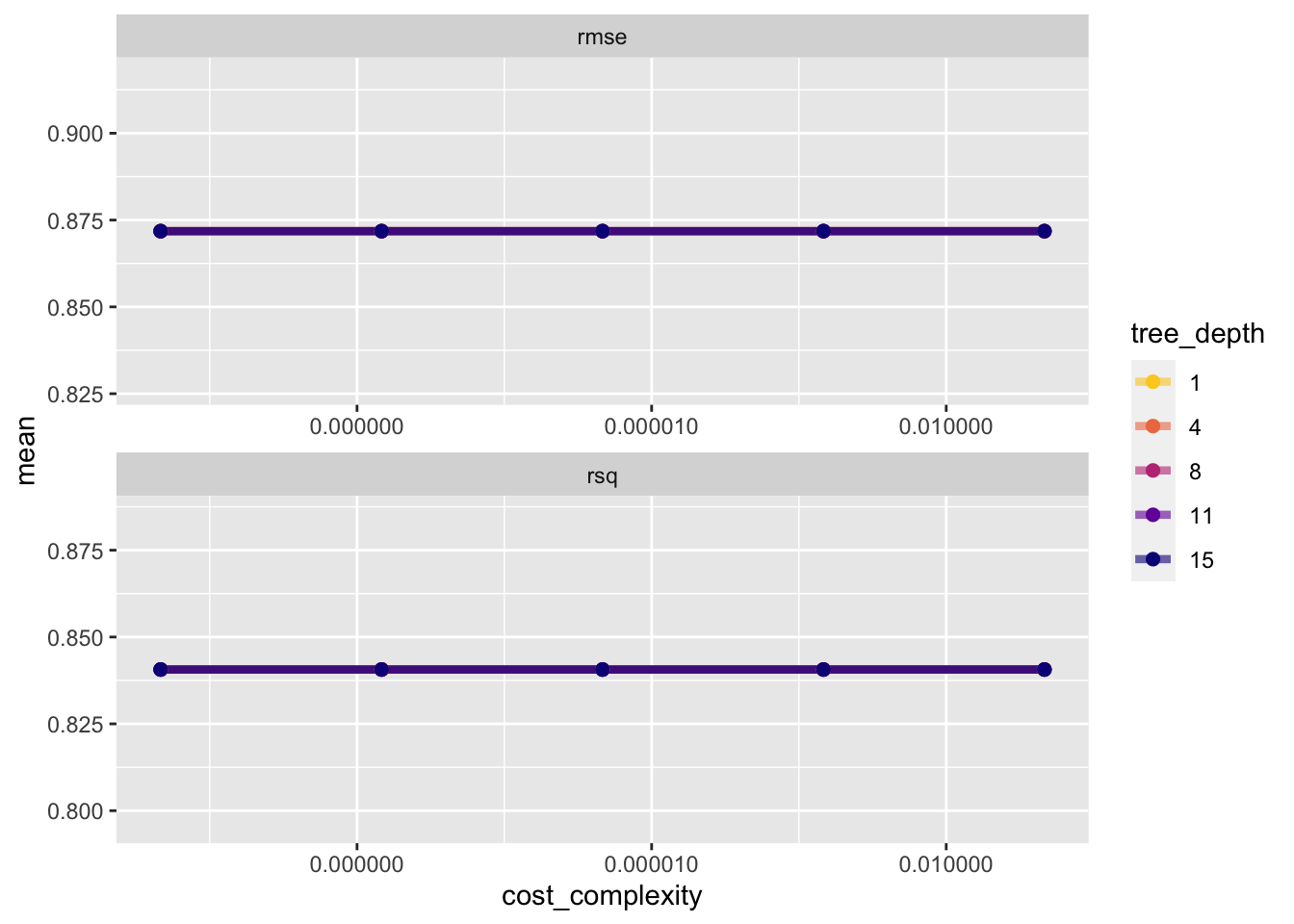
Once we have our tuning results, we can both explore them through visualization and then select the best result. The function collect_metrics() gives us a tidy tibble with all the results
dtree_resample %>%collect_metrics()
# A tibble: 50 × 8
cost_complexity tree_depth .metric .estimator mean n std_err .config
<dbl> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 0.0000000001 1 rmse standard 0.872 25 0.0152 Preprocess…
2 0.0000000001 1 rsq standard 0.841 25 0.00563 Preprocess…
3 0.0000000178 1 rmse standard 0.872 25 0.0152 Preprocess…
4 0.0000000178 1 rsq standard 0.841 25 0.00563 Preprocess…
5 0.00000316 1 rmse standard 0.872 25 0.0152 Preprocess…
6 0.00000316 1 rsq standard 0.841 25 0.00563 Preprocess…
7 0.000562 1 rmse standard 0.872 25 0.0152 Preprocess…
8 0.000562 1 rsq standard 0.841 25 0.00563 Preprocess…
9 0.1 1 rmse standard 0.872 25 0.0152 Preprocess…
10 0.1 1 rsq standard 0.841 25 0.00563 Preprocess…
# … with 40 more rows
══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: decision_tree()
── Preprocessor ────────────────────────────────────────────────────────────────
0 Recipe Steps
── Model ───────────────────────────────────────────────────────────────────────
Decision Tree Model Specification (regression)
Main Arguments:
cost_complexity = 1e-10
tree_depth = 1
Computational engine: rpart
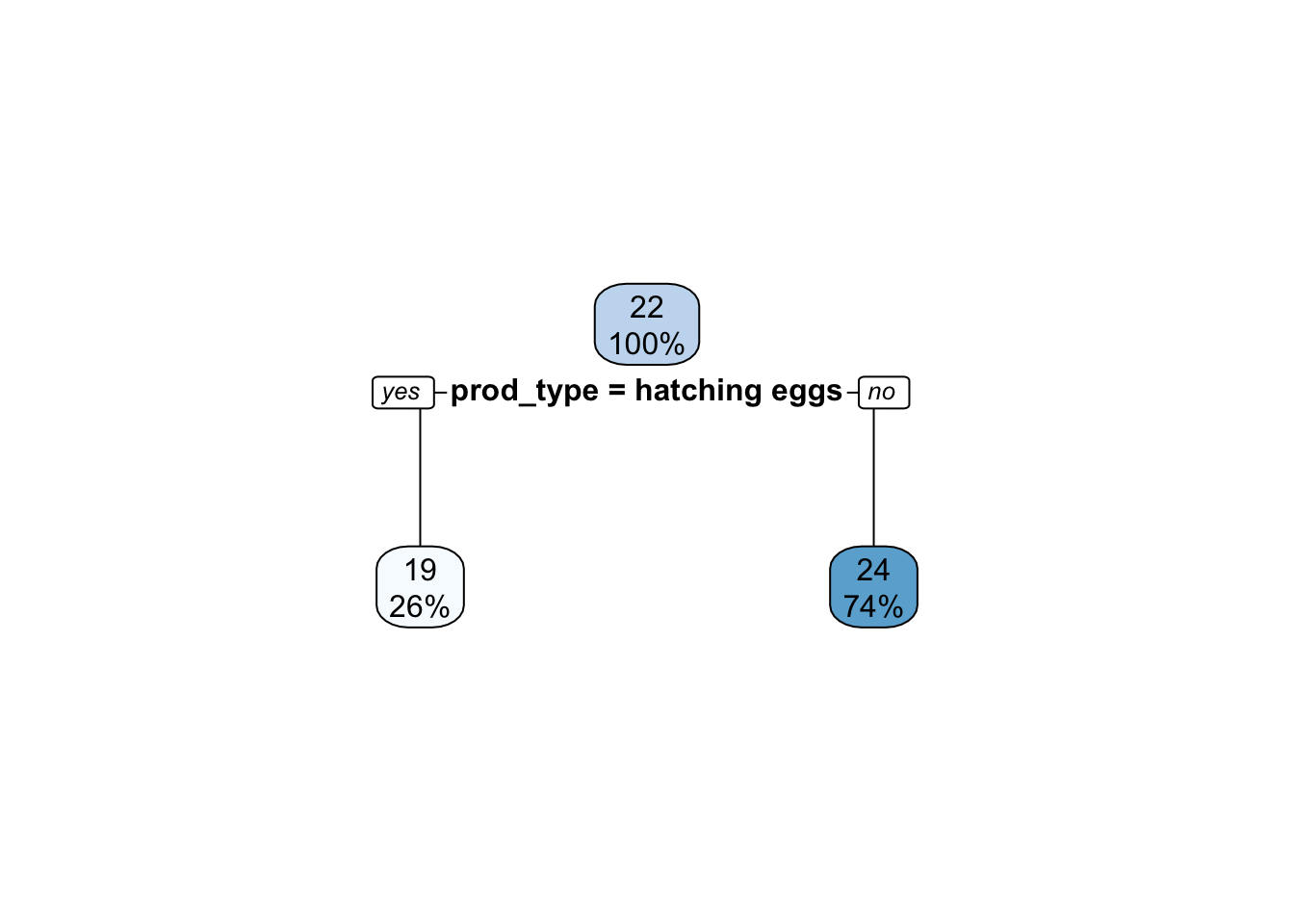
#Create workflow for fitting model to train predictionsdtree_final_fit <- dtree_final_wf %>%fit(train)
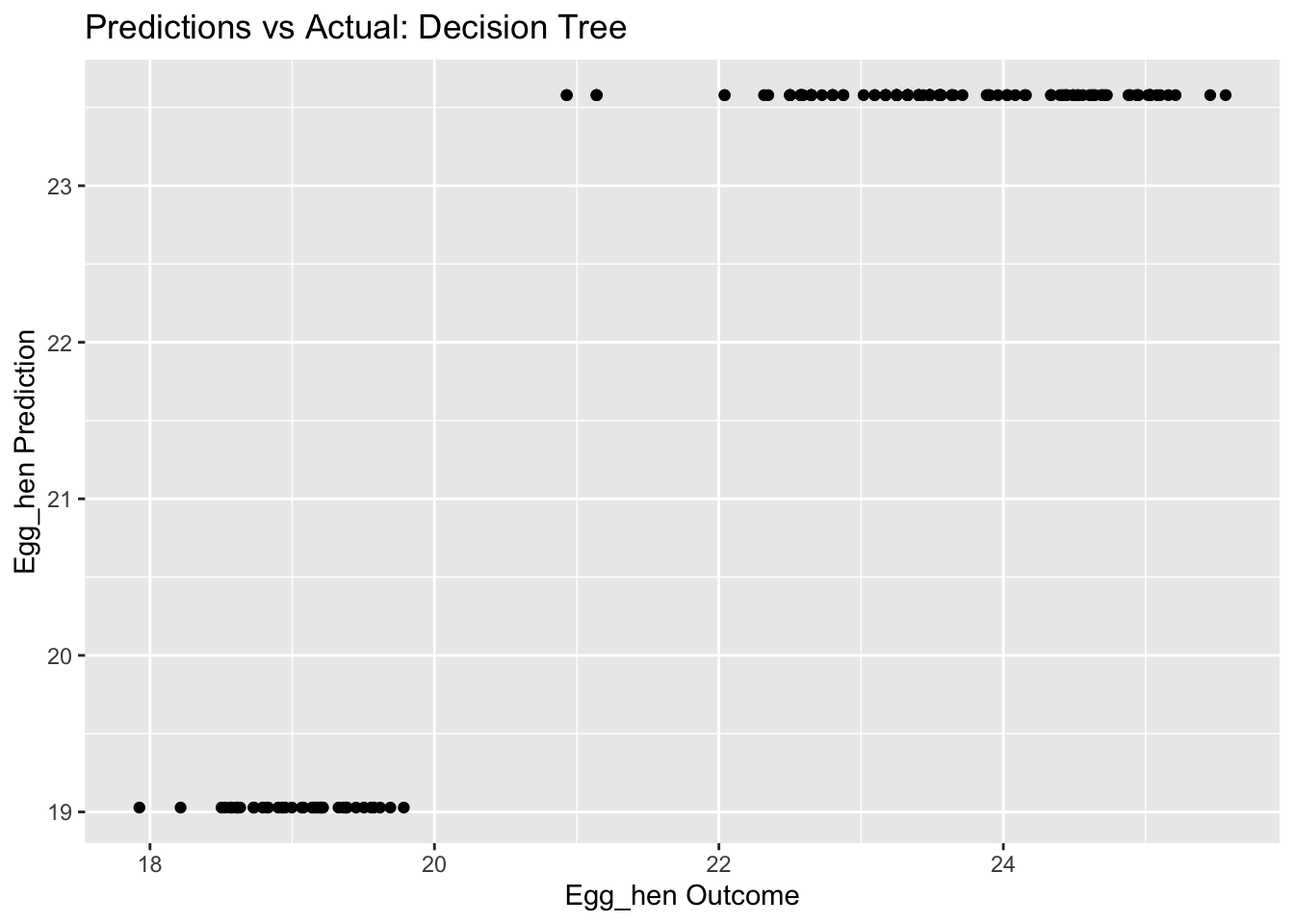
Calculating Residuals and Plotting Actual Vs. Predicted Values
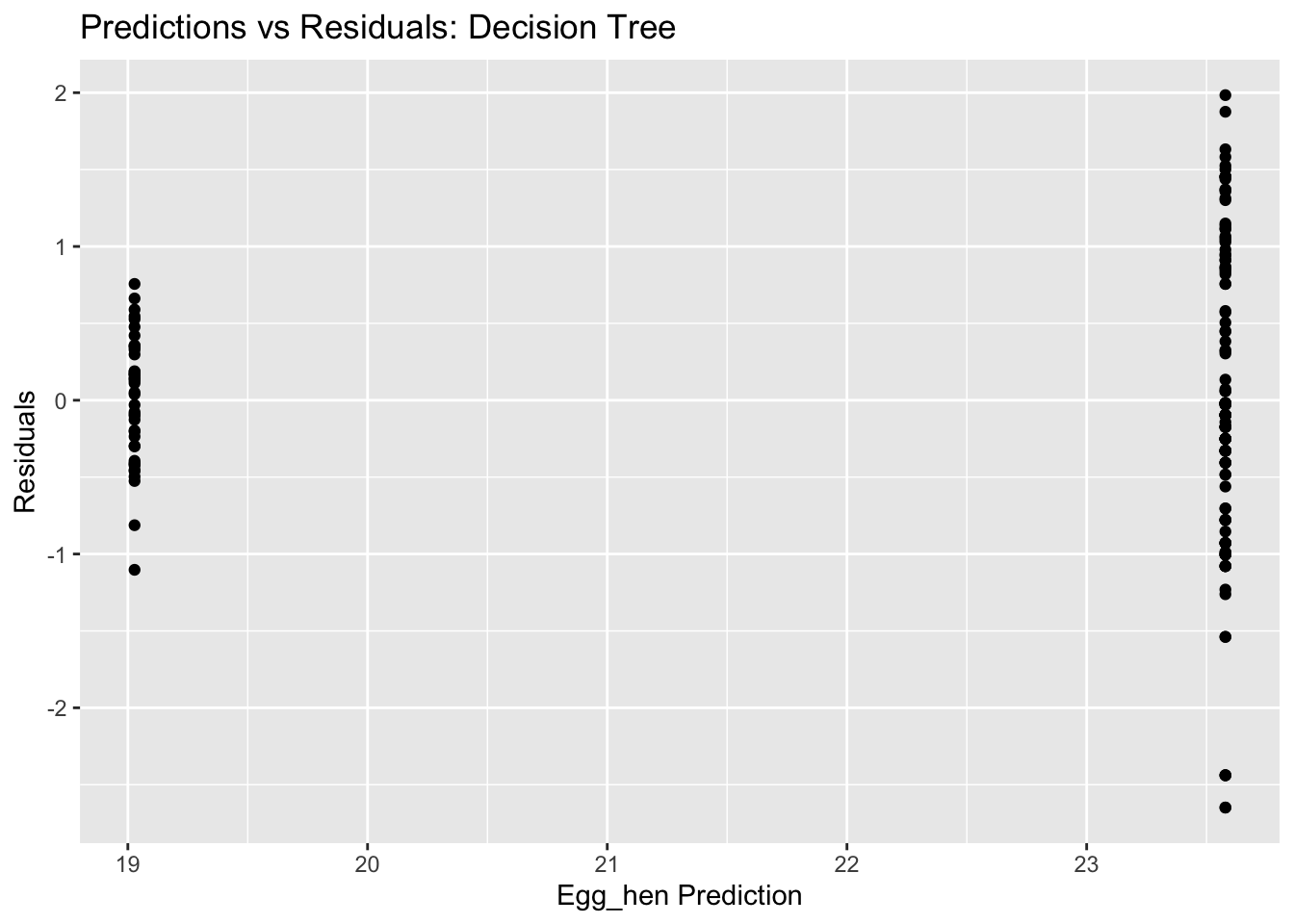
dtree_residuals <- dtree_final_fit %>%augment(train) %>%#use augment() to make predictions from train dataselect(c(.pred, egg_hen)) %>%mutate(.resid = egg_hen - .pred) #calculate residuals and make new row.dtree_residuals
i Creating pre-processing data to finalize unknown parameter: mtry
rf_resample %>%collect_metrics()
# A tibble: 23 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 1 3 rmse standard 0.872 25 0.0152 Preprocessor1_Model01
2 1 9 rmse standard 0.872 25 0.0153 Preprocessor1_Model02
3 1 27 rmse standard 0.872 25 0.0152 Preprocessor1_Model03
4 1 4 rmse standard 0.872 25 0.0153 Preprocessor1_Model04
5 1 13 rmse standard 0.872 25 0.0152 Preprocessor1_Model05
6 1 23 rmse standard 0.872 25 0.0152 Preprocessor1_Model06
7 1 21 rmse standard 0.872 25 0.0152 Preprocessor1_Model07
8 1 35 rmse standard 0.872 25 0.0153 Preprocessor1_Model08
9 1 12 rmse standard 0.872 25 0.0152 Preprocessor1_Model09
10 1 6 rmse standard 0.872 25 0.0152 Preprocessor1_Model10
# … with 13 more rows
Plot Model Performance
#Plot of actual train datarf_resample %>%autoplot()
Metrics: RMSE
#Showing best performing tree modelsrf_resample %>%show_best(n=1)
# A tibble: 1 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 1 39 rmse standard 0.872 25 0.0152 Preprocessor1_Model22
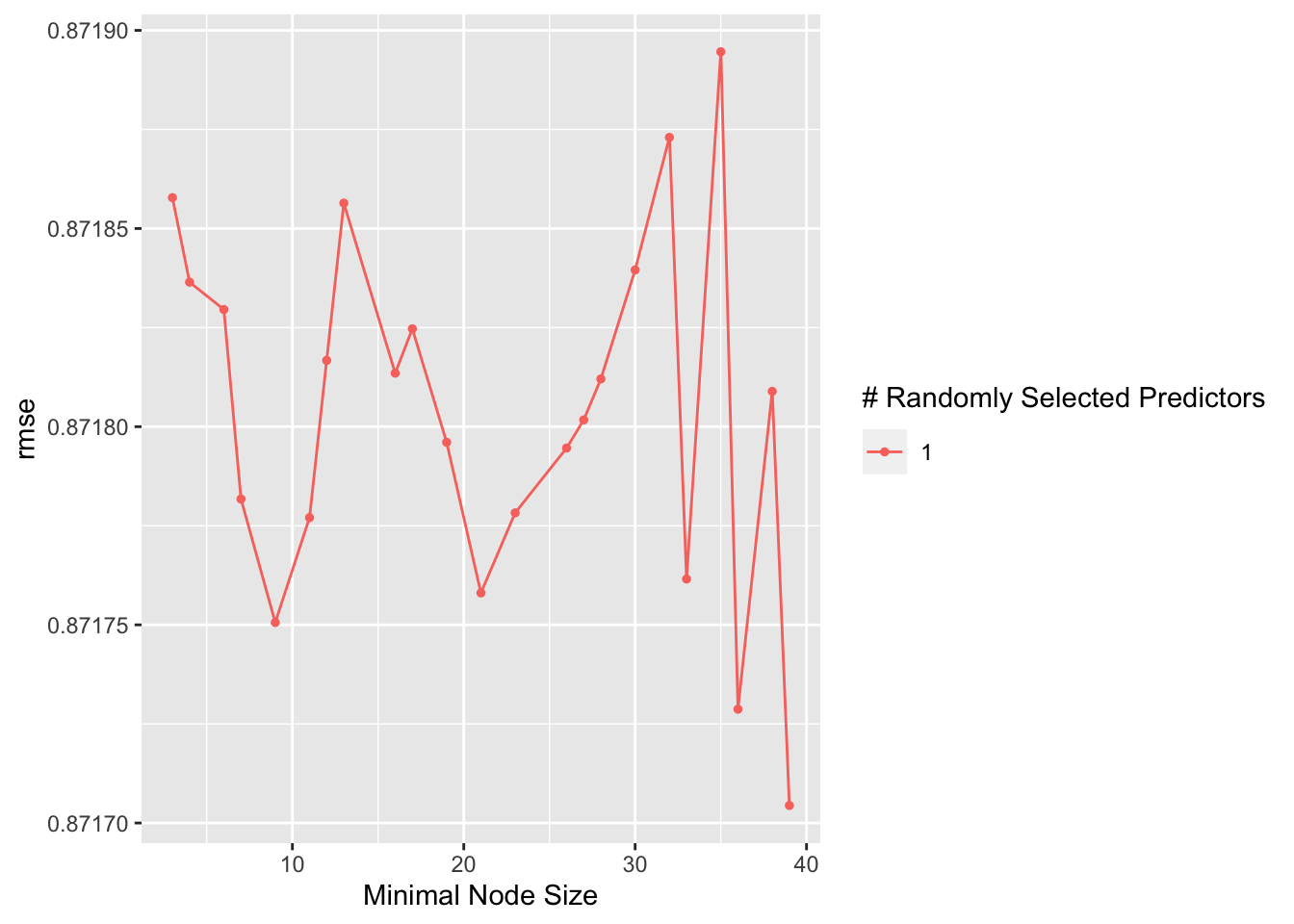
#Selects best performing modelbest_rf <- rf_resample %>%select_best(method ="rmse")
RMSE = 0.87 STD_ERR = 0.015
Create Final Fit
rf_final_wf <- rf_wf %>%finalize_workflow(best_rf)#Create workflow for fitting model to train_data2 predictionsrf_final_fit <- rf_final_wf %>%fit(train)
Calculate Residuals
rf_residuals <- rf_final_fit %>%augment(train) %>%#use augment() to make predictions from train dataselect(c(.pred, egg_hen)) %>%mutate(.resid = egg_hen - .pred) #calculate residuals and make new row.rf_residuals
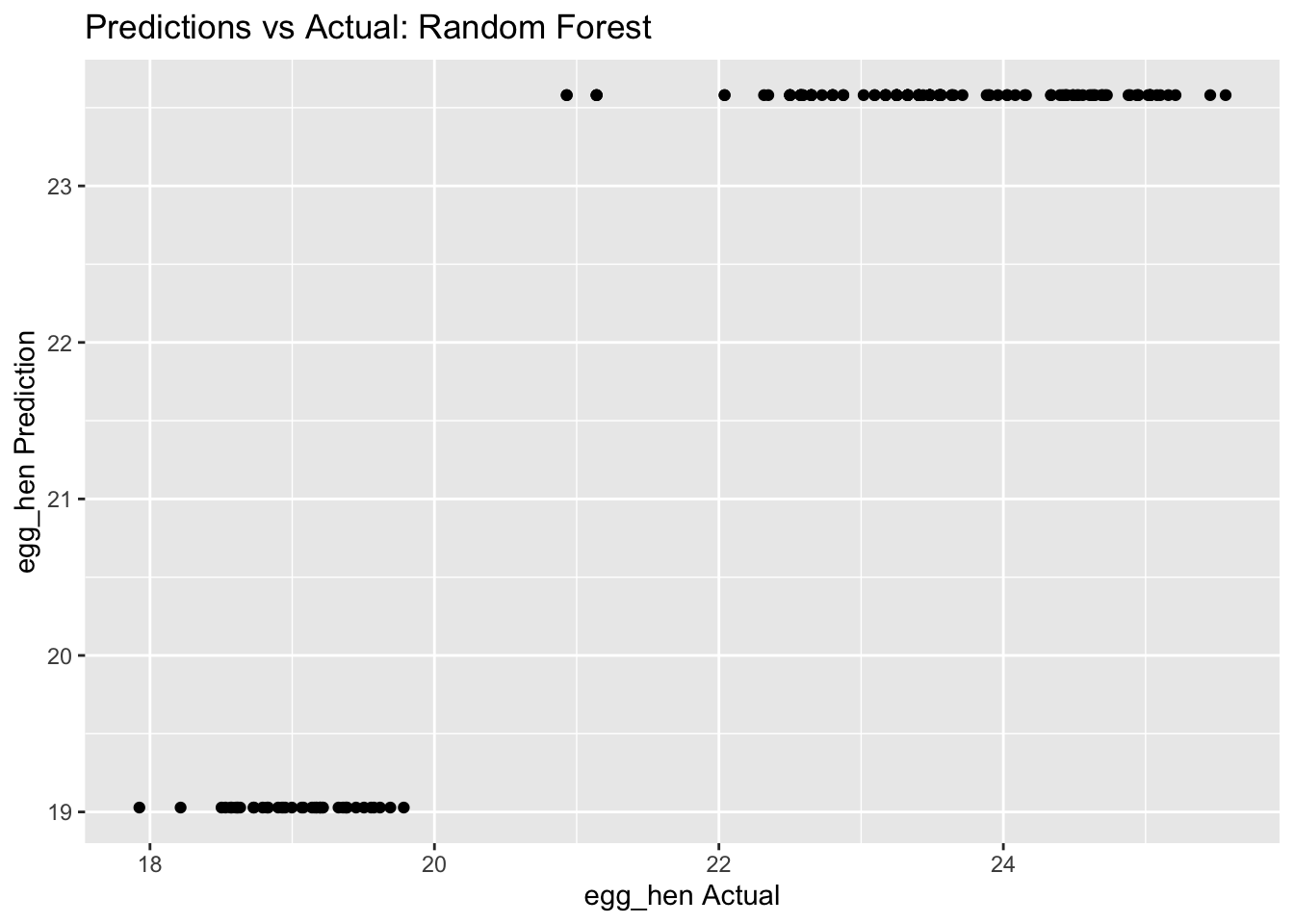
Model Predictions from Tuned Model vs Actual Outcomes
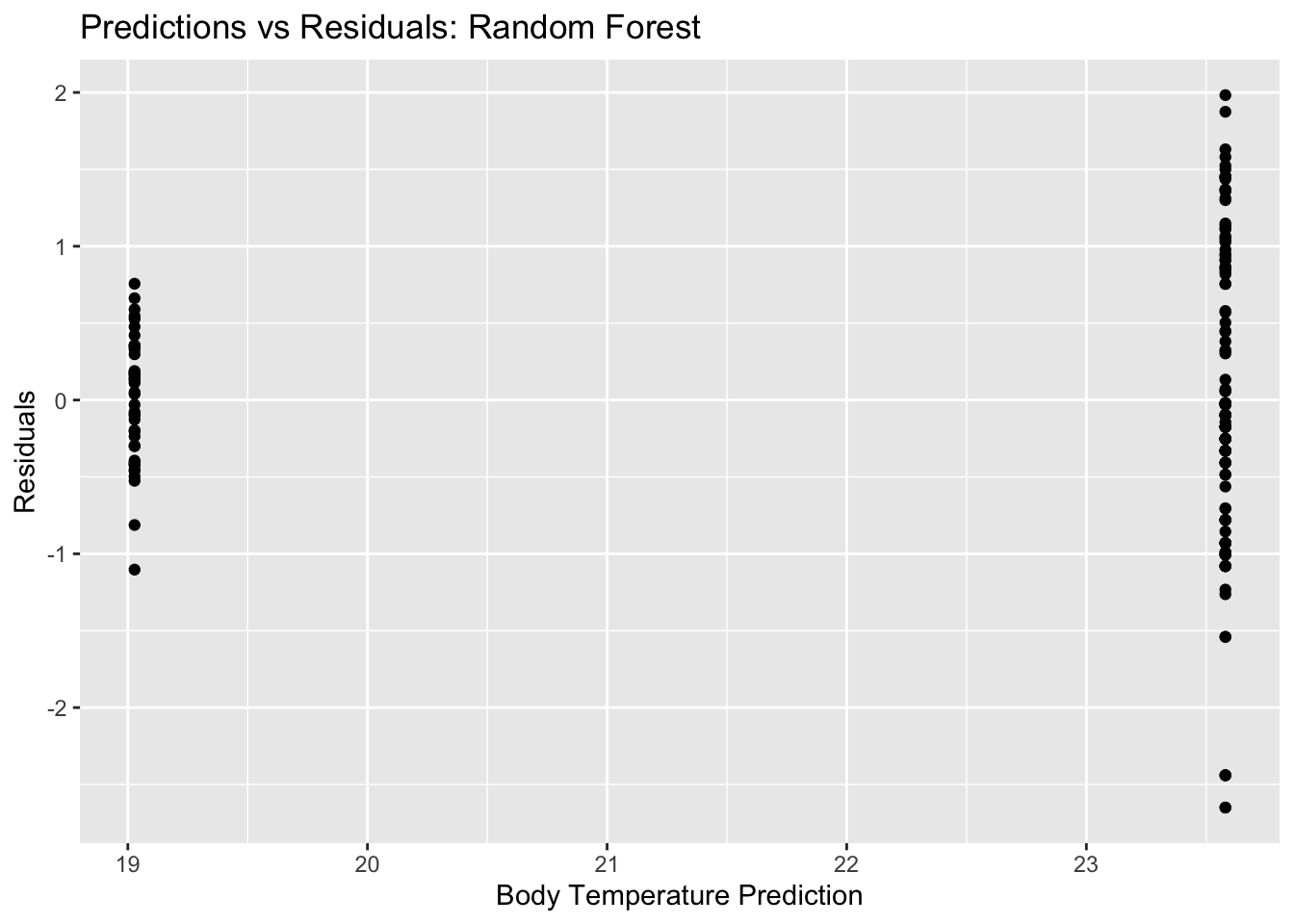
rf_pred_plot <-ggplot(rf_residuals, aes(x = egg_hen, y = .pred)) +geom_point() +labs(title ="Predictions vs Actual: Random Forest", x ="egg_hen Actual", y ="egg_hen Prediction")rf_pred_plot
rf_residual_plot <-ggplot(rf_residuals, aes(y = .resid, x = .pred)) +geom_point() +labs(title ="Predictions vs Residuals: Random Forest", x ="Body Temperature Prediction", y ="Residuals")plot(rf_residual_plot) #view plot
Final Assessment
In order to pick a model that I believe is best for my hypothesis, I must (1) understand the data and question (2) use visual plots, and (3) metrics (e.g. RMSE) to assess performance. Based on these three attributes, I believe that the one-way ANOVA is the best model to use in this case. I am working with a continuous outcome (eggs per hen) and a categorical independent variable (production type) and would like to assess the two means between hatching and table eggs. This model is simple and efficient, and properly addresses the questions. Additionally, the RMSE of the actual model (0.87) was lower than the null model (2.18) indicating a better performance.
The Random Forest Model also had a lower RMSE value (0.87), ut the plot produced depicts a fluctuation in performance with node size. The decision tree is a simple model, but in this case not very informative as we only had two outcomes.
ANOVA on Test Data
#Modelanova_test<-aov(egg_hen ~ prod_type, data = test)summary(anova_test)
Df Sum Sq Mean Sq F value Pr(>F)
prod_type 1 210.81 210.81 204.9 <2e-16 ***
Residuals 53 54.52 1.03
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The data used for this exercise was sourced from The Humane League’s US Egg Production dataset by Samara Mendez. It tracks cage-free hens and the supply of cage-free eggs relative to the overall numbers of hens and table eggs in the United States.
Cleaning
Data cleaning involved making a new column in the egg data set “egg_hen” which represents the number of eggs per hen. Variables within columns were also renamed for convenience.
Visualization
To explore the data, plots were made to depict various trends between the variables (e.g. percentage of cage free hens and eggs over time, eggs per hen over time, eggs per hen across production type/process). From this exploration, we could see a drastic difference in eggs per hen between table and hatching production type. This lead us to explore the relationship between production type (hatching or table) on eggs produced per hen.
Modeling
Final cleaning was conducted (eliminating undesired columns) and the data was split into training and test data (70:30). A null linear model was run for comparison of metrics. Four models were tested in this exercise:
Linear Model
ANOVA Model
Tree Model
Regression Decision Tree
Random Forest Model.
Metrics were run (Primarily RMSE) and compared to the Null model to assess performance. Additionally, visualization methods were used in conjunction with the performance metrics.
Conclusion
Based on the metrics, the question, and the plots, the ANOVA model was chosen, and again run but on the test data. Ultimately, it had a higher RMSE than the train data, but still lower than the null ANOVA, suggesting that this model can be adequate in its ability to address our question.